Hello World!
0 写在前面
这篇文章写给那些有编程经验无网络经验,有python经验无爬虫经验,有网络经验无验证码识别经验的人,也算是自己从零到有,从完全小白开始奋战刷课机(一个带验证码识别的自动选课程序,学校的抢课太凶残了)两天两夜的经验总结,想做一个非常详细的教程,希望读者看完后,刷课机也基本写完了,省下时间可以多看一些其他书。 本文线索:【1】环境设置;【2】网络部分;【3】验证码识别部分。
1 环境配置
不推荐Windows系统,因为很多第三方的库只考虑了Linux环境下的编译,比如py文件里的路径是用 ‘/’ 但Windows环境下的路径是 ‘\’,这就非常坑爸爸了,还有诸如新系统装了VS2013,但是很多源代码编译的时候要用VS2008或MinGW,安装就很繁琐了。 推荐Linux系列的系统,双系统虚拟机萝卜青菜各有所爱~ python版本分为2.X系和3.X系,因为我使用的第三方库有PIL和svmlight,PIL全称是Python Image Library,目前官方只支持2.X,于是我推荐大家使用2.X系列的。
安装pip,一个python环境必备的软件,帮助python安装管理第三方插件,python-dev是安装其他软件首先要具备的,否则可能编译安装的时候会出现缺少Python.h文件等奇怪问题。
安装PIL,一开始安装的库是为了支持jpeg,png等格式的图片,有时候PIL安装出现问题,要用pillow,具体作用不太清楚。
安装svmlight,python有各种各样的数学库,甚至可以用OpenCV的库来做验证码识别(个人非常喜欢OpenCV),因为我们目标明确,这里推荐一个轻量级svm库,它貌似只有四个函数可以调用,训练model,保存model,读取model,用model做预测识别,非常轻量级非常方便。
$ sudo apt-get install python-dev
$ sudo apt-get install python-pip
$ sudo apt-get install libjpeg-dev libfreetype6-dev zlib1g-dev
$ pip install -I pillow
$ pip install PIL --allow-external PIL --allow-unverified PIL
$ pip install svmlight
至此环境全部配置完了,可以测试一下:
$ python
$ >>> import Image
$ >>> import svmlight
如果没有报错什么的,恭喜你,安装成功了:),这些软件都比较成熟了,如果有奇怪的问题,复制到google中也比较容易解决~ 如果有python的小白不懂python的语法的话,建议去w3cschool花几个小时自学一下,很容易的。 补充一下个人习惯的程序头部:
#coding=utf-8 # 全文utf-8编码
import urllib, urllib2, cookielib # 网络相关库
from PIL import Image # 图形处理库
import sys # 系统相关的库
import os # 操作系统读写的库
import svmlight # 做svm用的库
import re # 正则表达式的库
import time # 时间库
reload(sys) # 余伊芙随手替我敲上的三行代码,从此
sys.setdefaultencoding('utf-8') # 字符串操作再无奇怪问题,无限膜拜,
del sys.setdefaultencoding # 余神博客 http://jackyyf.com
2 网络部分
网络使用urllib和urllib2的库,服务器要保证发给浏览器的验证码图片和用户输入的验证码一一对应,会用到cookie这个东西,在程序的一开始为程序“安装”cookie:
cookie_jar = cookielib.LWPCookieJar()
cookie_support = urllib2.HTTPCookieProcessor(cookie_jar)
http_handler = urllib2.HTTPHandler(debuglevel=0) # 为1时输出调试信息
opener = urllib2.build_opener(cookie_support, http_handler)
urllib2.install_opener(opener)
打开一个网址,并下载相应html文件或图片到本地:
get_url = 'http://www.lyq.me'
page = urllib2.urlopen(get_url)
open('page.html', 'w').write(page.read().decode('utf-8'))
这时候,你的cookiie_jar已经有相应网站的cookie了,可以提取后输出到屏幕上:
#format cookit
cookies = ''
for index, ck in enumerate(cookie_jar):
cookies = cookies + ck.name + '=' + ck.value + ';'
cookie = cookies[:-1]
print cookie
假设网页中还提供了一个和验证码一一对应的token数值,我们要把它提取出来,到时和识别出的验证码一起作为表单POST上去,要提去某一个文件里的特定字符,就需要正则匹配了:
string = r'src="image\.do\?token=(\d+)" />' # r' ' 表示原封不动保留内部符号
# 待匹配的部分用小括号括起来
# 原串为 src="image.do?token=1234" />
src = re.compile(string) # 用re库对字符串编译
re_bin = src.findall(f) # f=page.read()
if len(re_bin) == 0: # 一个都未匹配到
return 'NULL'
else: # 匹配成功,返回token
return re_bin[0]
对于正则表达式不熟悉的同学不要紧,可以花二十分钟入门一下:http://deerchao.net/tutorials/regex/regex.htm 主要学习一下匹配空格、匹配字母、匹配数字都是什么符号,还有转义符号,取反符号等 http://www.regexr.com 一个正则匹配的在线网站,下面把网页复制进去,然后可以在线测试你的正则规则是否合法
假设我们现在有了token和根据图片识别出的验证码,下一步要把他们组合成表单POST上去: 打开Chrome或火狐的F12,手动输入用户名密码验证码之后,查看网络通信,有两大类,GET和POST,查找POST,你会看到其中一个有你刚刚填的信息,那就是我们需要的,我们需要这三个,Request URL, Request Headers, Form Data,这些信息很多都是不变的,写成字符串就行,要变化的地方用变量写上去,例如:(因为Windows画图板比较方便,就在Windows环境下截图了,不要在意细节…)
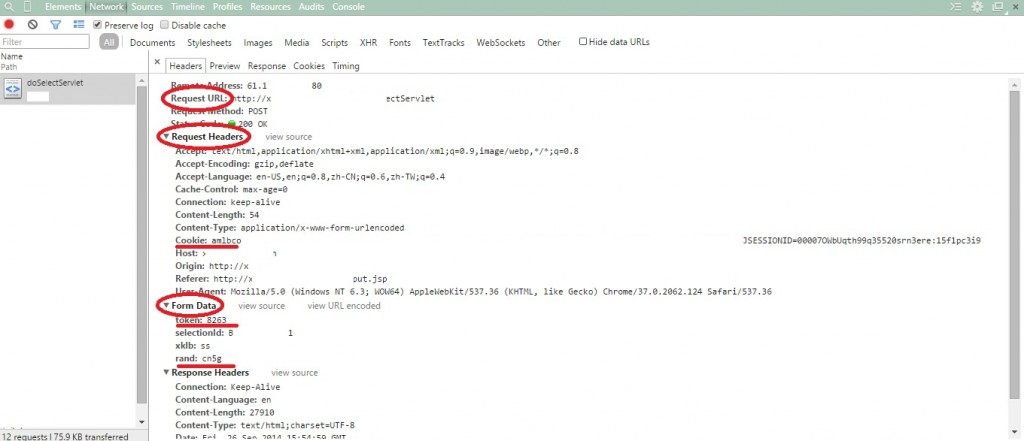
post_url = 'http:// '
request_headers = {
'Accept':'text/html, ...',
....
'Cookie':cookie,
....
}
form_data = {
'token':token,
'selectionId':selectID,
'xklb':'ss',
'rand':validcode
}
data = urllib.urlencode(form_data) # encode data
request = urllib2.Request(post_url, data, request_headers) # encode2Request
result_page = urllib2.urlopen(request)
f = result_page.read()
open('result.html', 'w').write(f.decode('utf-8'))
判断是否登录成功可以检查result.html的内容,至此网络部分讲解完毕,有错误的地方欢迎评论!
3 验证码识别部分
(写于2022年)
第三部分果然就此拖更就没了哈哈, svmlight 还是比较简单的, 可以看看官方文档训练一个分类器, 如今2022年已经不是 SVM 而是 CNN 的天下了.